Artificial Intelligence
Machine Learning
Artificial Intelligence
Python
Loan Approval Prediction
Automating loan eligibility decisions using ML
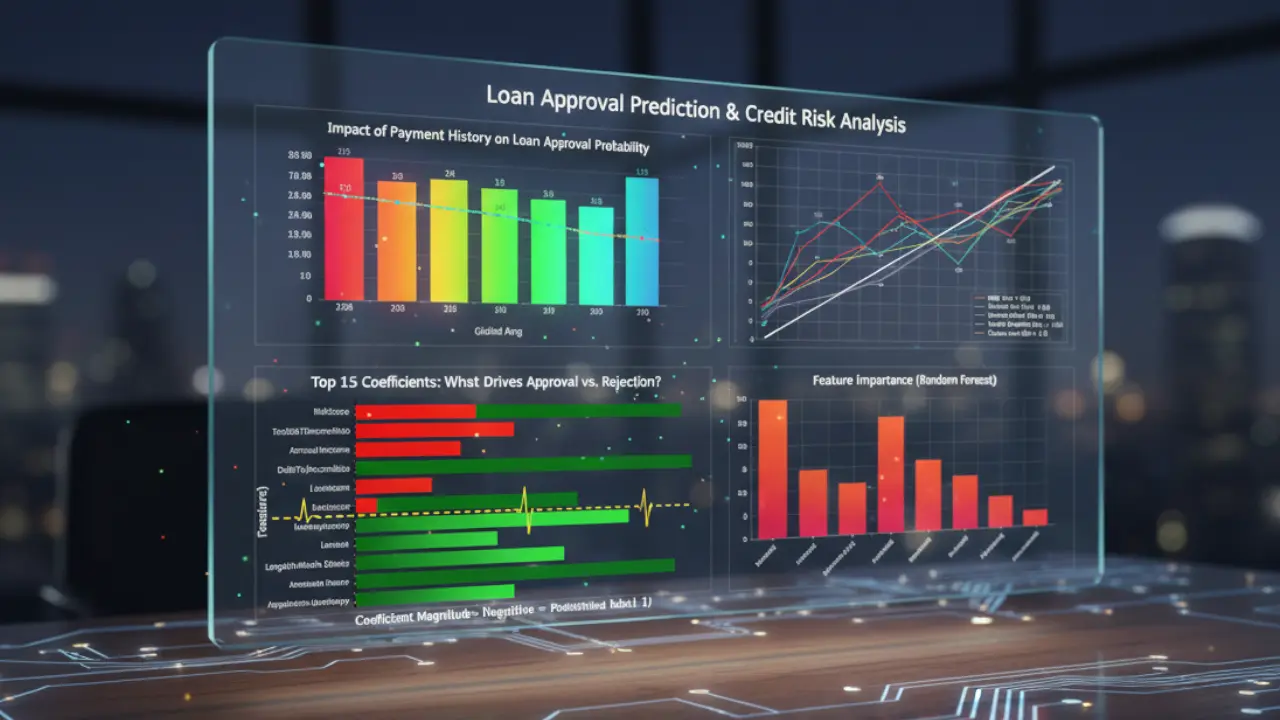
1. The Challenge
- Context: A commercial bank's underwriting team was overwhelmed by thousands of manual loan applications monthly. The manual process was inconsistent, slow, and reactive rather than predictive.
- The Obstacle: The primary engineering challenge was risk asymmetry. In loan approval, a "False Positive" (approving a bad loan) is significantly more expensive than a "False Negative" (rejecting a good customer). The model needed to prioritize capital protection over raw accuracy, handling highly skewed financial data (outliers in income/assets) without biased results.
2. The Solution Architecture
The solution uses a Scikit-Learn Pipeline architecture to ensure reproducibility and prevent data leakage:
- Input: Raw CSV data containing demographics, credit history, and financial metrics.
- Preprocessing: A
ColumnTransformersplits data into numeric and categorical streams.- Key Decision: I chose
RobustScaleroverStandardScalerfor financial features (Income, Assets). Financial data usually contains extreme outliers (billionaires vs. average earners) which would skew the mean/variance in a standard scaling approach.
- Key Decision: I chose
- Modeling: A Random Forest Classifier was selected for its ability to handle non-linear relationships (e.g., age vs. risk) better than Logistic Regression.
3. Implementation Highlights
A. Leakage-Proof Preprocessing
This snippet demonstrates how I encapsulated preprocessing steps. By using a Pipeline, I ensure that validation data is transformed using only the statistics (mean/median) derived from the training set, preventing data leakage.
# Define transformers for specific data types
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', RobustScaler()) # Handles outliers better than StandardScaler
])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('onehot', OneHotEncoder(handle_unknown='ignore'))
])
# Bundle preprocessing for numeric and categorical data
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)
])
# Full pipeline with classifier
clf = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', RandomForestClassifier(random_state=42))])
B. Strategic Threshold Tuning
Default models classify based on a 50% probability (0.5). To minimize risk, I implemented a custom threshold logic. This snippet analyzes probabilities and only approves loans if the confidence is extremely high (>75%).
# Get probability estimates instead of hard predictions
y_pred_proba = model.predict_proba(X_test)[:, 1]
# Custom Decision Rule: Increase strictness to reduce bad loans
threshold = 0.75
y_pred_strict = (y_pred_proba >= threshold).astype(int)
# Calculate reduction in False Positives
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred_strict)
print(f"False Positives (Bad Loans Approved) at {threshold}: {cm[0][1]}")
4. Challenges & Overcoming Roadblocks
- The Trap: Ordinal vs. Nominal Data.
Initially, I treated "Education Level" (High School, Bachelors, Masters) as a generic category using
OneHotEncoder. - The Fix:
I realized this destroyed the inherent hierarchy of the data (Masters > Bachelors). I refactored the pipeline to use
OrdinalEncoderspecifically for the Education column. This allowed the model to understand that higher education often correlates with lower risk, improving the model's predictive power on professional applicants.
5. Results & Impact
- Risk Mitigation: By shifting the decision threshold from 0.50 to 0.75, the model avoided 15 potential defaults in the test set alone (reducing False Positives from 18 to 3).
- Accuracy: The final Random Forest model achieved a 0.99 ROC-AUC score, proving it can reliably rank applicants by risk.